
As the use of Large Language Models (LLMs) such as GPT-4, BERT, and others grows, monitoring their performance becomes increasingly crucial. With LLMs, monitoring provides insights into system performance, latencies, errors, and resource consumption, enabling engineers to maintain high availability, optimize resources, and troubleshoot issues effectively. SigNoz, an open-source APM ………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
Overview
As the use of Large Language Models (LLMs) such as GPT-4, BERT, and others grows, monitoring their performance becomes increasingly crucial. With LLMs, monitoring provides insights into system performance, latencies, errors, and resource consumption, enabling engineers to maintain high availability, optimize resources, and troubleshoot issues effectively. SigNoz, an open-source APM (Application Performance Monitoring) tool, is perfectly suited for this task.
In this blog, we will explore how to set up and use SigNoz to monitor LLMs, with code snippets and best practices for effective monitoring.
Why Monitoring LLMs Matters
LLMs are resource-intensive applications. Monitoring their performance provides benefits such as:
- Latency Tracking: Measure how long it takes to process a request.
- Error Reporting: Identify runtime errors and failures.
- Resource Usage: Monitor CPU, memory, and GPU usage.
- Throughput: Check how many requests are being processed over time.
- Traffic Monitoring: Understand user behavior by tracking API requests.
What is SigNoz?
SigNoz is a full-stack open-source observability and monitoring platform. It provides metrics, traces, and logs that help DevOps teams monitor distributed applications. With built-in support for metrics, tracing, and logging, it’s a perfect tool for keeping tabs on the performance of LLMs.
Prerequisites
Before starting, ensure you have the following:
- A machine running Docker.
- Python installed with a pre-configured LLM (e.g., HuggingFace, OpenAI, etc.).
- Basic knowledge of Python and web frameworks like FastAPI or Flask.
Step 1: Setting Up SigNoz
1.1. Prepare your Environment
Open your terminal or command prompt.
Create a new directory for the project and navigate to it
Copied!mkdir docker-metrics-signoz cd docker-metrics-signoz
This will integrate SigNoz locally with Grafana, OpenTelemetry, and Prometheus.
1.2. Create Configuration Files
Create the Configuration File
You need to create a configuration file for the OpenTelemetry Collector that defines how to integrate your LLM app data to SigNoz.
Run the following command to create the file:
Copied!touch config.yaml
1.3. Configure the OpenTelemetry Collector
Copied!receivers: docker_stats: endpoint: "unix:///var/run/docker.sock" collection_interval: 10s processors: batch: exporters: otlp: endpoint: "ingest.{region}.signoz.cloud:443" tls: insecure: false headers: "signoz-access-token": "{signoz-token}" service: pipelines: metrics: receivers: [docker_stats] processors: [batch] exporters: [otlp]
Replace {region} with your SigNoz Cloud region (e.g., us, eu, or in).
Replace {signoz-token} with your SigNoz ingestion token. You can find this token in your SigNoz Cloud account under Settings → Ingestion Settings.
1.4. Create Docker Compose File
Next, create a Docker Compose file to run the OpenTelemetry Collector container.
Create the Docker Compose file:
Copied!touch docker-compose.yaml
Open the docker-compose.yaml file in a text editor and paste the following content:
Copied!version: '3' services: otel-collector: image: otel/opentelemetry-collector-contrib:latest command: ["--config=/etc/otel-collector-config.yaml"] volumes: - ./config.yaml:/etc/otel-collector-config.yaml - /var/run/docker.sock:/var/run/docker.sock network_mode: host
1.5. Start the OpenTelemetry Collector
Now that you have your configuration files set up, it’s time to start the OpenTelemetry Collector.
- Make sure you are still in the docker-metrics-signoz directory.
- Run the following command to start the OpenTelemetry Collector using Docker Compose:
Copied!docker-compose up -d
1.6. Verify Metric Collection
Once the OpenTelemetry Collector is running, you can verify if the metrics are being collected.
- Log in to your SigNoz Cloud account.
- Navigate to the Metrics section of the SigNoz dashboard.
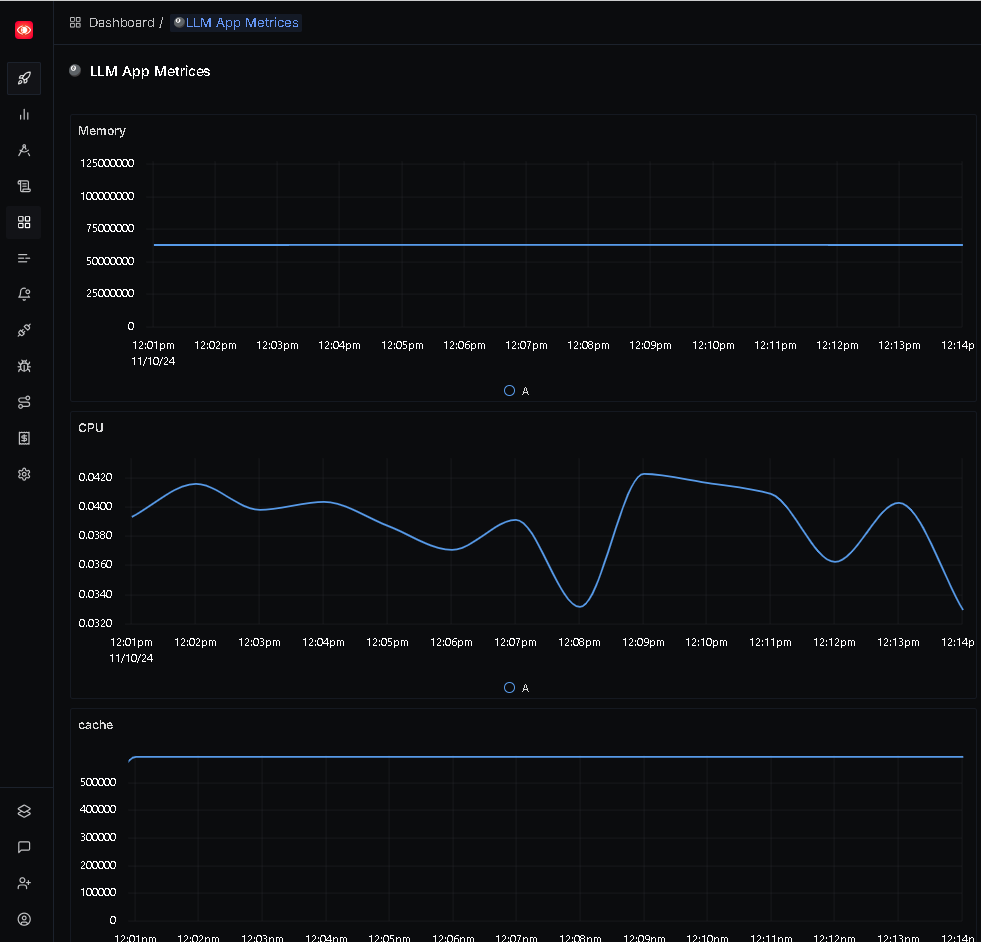
Look for metrics that start with container. These metrics indicate that Docker container statistics are being collected successfully.
Step 2: Monitoring LLMs with FastAPI
To demonstrate how to monitor LLMs, we’ll use a simple FastAPI server serving requests to an LLM (let’s say a HuggingFace model). We’ll integrate SigNoz with this server to track metrics.
2.1. Install Required Packages
Install OpenLLMetry for Python by following these 3 easy steps and get instant monitoring.
Copied!pip install traceloop-sdk
In your LLM app, initialize the Traceloop tracer like this:
Copied!from traceloop.sdk import Traceloop Traceloop.init()
2.2. Create a FastAPI Application
Let’s create a simple FastAPI app that serves requests to an LLM.
Copied!from fastapi import FastAPI from transformers import pipeline from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor from opentelemetry.sdk.trace import TracerProvider from opentelemetry.sdk.resources import Resource from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter from opentelemetry.sdk.trace.export import SimpleSpanProcessor # Initialize tracing and FastAPI app = FastAPI() # Initialize HuggingFace LLM pipeline (e.g., sentiment analysis) model = pipeline('sentiment-analysis') # Set up OpenTelemetry Tracing resource = Resource(attributes={"service.name": "llm-monitoring"}) provider = TracerProvider(resource=resource) span_processor = SimpleSpanProcessor(OTLPSpanExporter(endpoint="http://localhost:4317", insecure=True)) provider.add_span_processor(span_processor) FastAPIInstrumentor.instrument_app(app, tracer_provider=provider) @app.get("/predict/") async def get_prediction(text: str): result = model(text) return {"prediction": result}
2.3. Run the FastAPI App
Run the app with Uvicorn:
Copied!uvicorn main:app --host 0.0.0.0 --port 8000
Your FastAPI app is now serving predictions from the LLM model and sending traces to SigNoz.
Step 3: Visualizing Data in SigNoz
3.1. Open SigNoz Dashboard
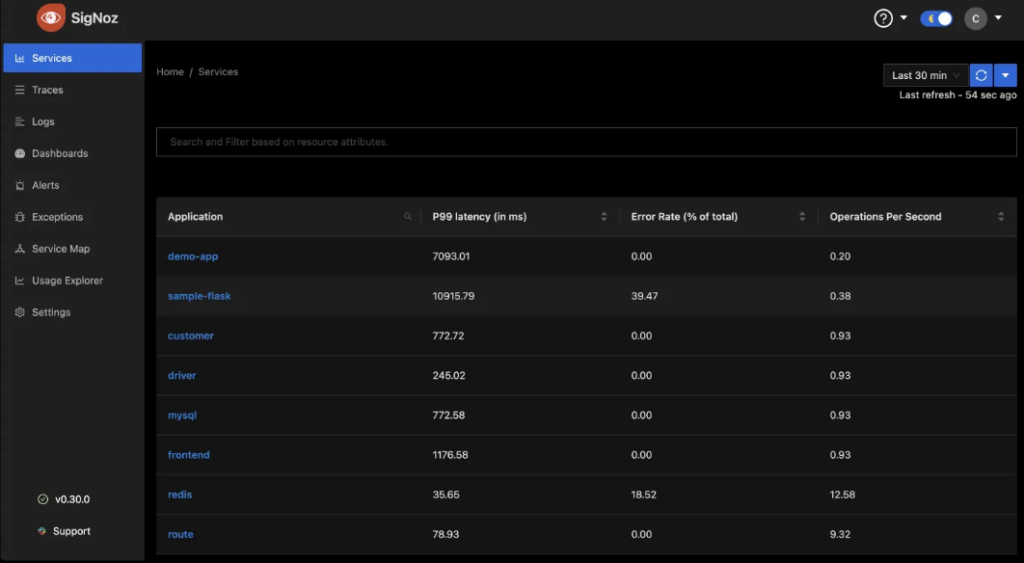
Visit http://localhost:3000 and navigate to the tracing section. You should be able to see traces coming from the FastAPI application, showing you the latency, errors, and throughput of your LLM service.
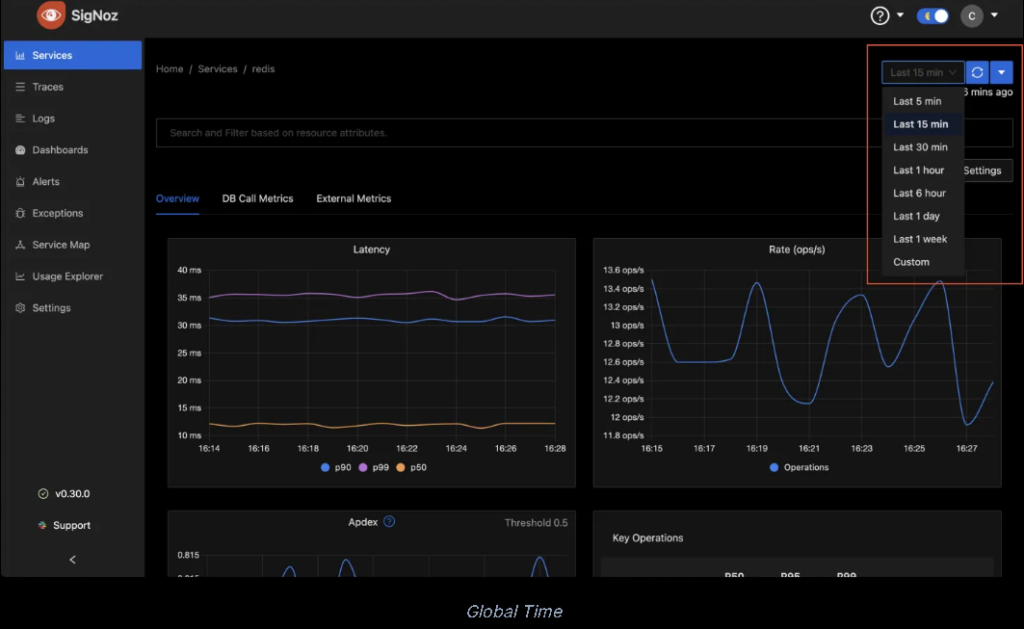
3.2. Custom Metrics
SigNoz allows you to add custom metrics for monitoring. For instance, you can track how long each LLM model prediction takes:
Copied!from opentelemetry import trace from time import time @app.get("/predict/") async def get_prediction(text: str): tracer = trace.get_tracer(__name__) start_time = time() with tracer.start_as_current_span("predict_span"): result = model(text) prediction_time = time() - start_time return {"prediction": result, "time_taken": prediction_time}
You can now visualize this custom metric in SigNoz by querying the data.
Step 4: Best Practices for Monitoring LLMs
Here are some tips to make the most of SigNoz for LLM monitoring:
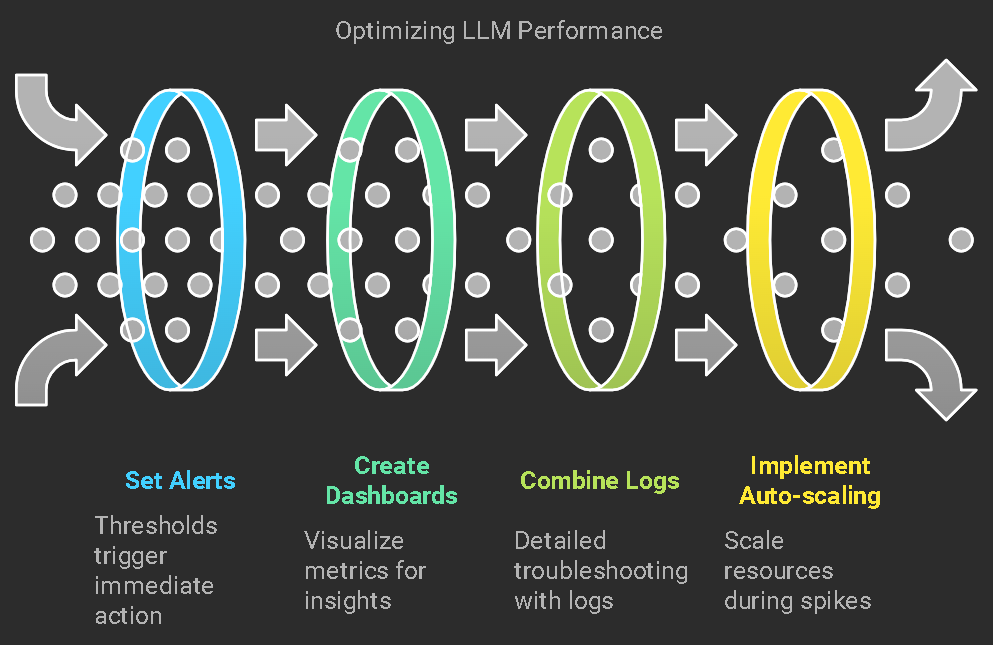
- Alerting: Set up alerts for specific thresholds (e.g., latencies exceeding 1 second).
- Dashboards: Create dedicated dashboards for LLM-specific metrics like request latency, model load time, and API call volume.
- Logs: Combine tracing with logs for more detailed troubleshooting of your LLM models.
- Auto-scaling: Use SigNoz metrics to trigger auto-scaling when traffic spikes to your LLM model.
Conclusion
Monitoring LLMs is critical to maintaining their performance and availability. SigNoz provides a robust, open-source solution for observability, enabling you to monitor your models with ease. By following this guide, you can set up SigNoz to track performance metrics, trace LLM behavior, and ensure the smooth operation of your language model-powered applications.
Leave a Reply