
As Kubernetes keeps progressing, the need for storage management becomes
As Kubernetes keeps progressing, the need for storage management becomes crucial. The chosen storage provider tools do not follow Kubernetes recommended methods. Also bring innovative capabilities to enable organizations to optimize storage resources and ensure a seamless and resilient application deployment experience.
As Kubernetes keeps progressing, the need for storage management becomes crucial. The chosen storage provider tools do not follow Kubernetes recommended methods. Also bring innovative capabilities to enable organizations to optimize storage resources and ensure a seamless and resilient application deployment experience.
Kubernetes is an open-source platform for automating deployment, scaling, and management of containerized applications. It is widely used for building and running cloud native applications that can run anywhere, on any cloud, and on any infrastructure. However, one of the challenges of using Kubernetes is how to handle persistent data for stateful workloads, such as databases, message queues, analytics, etc. Stateful workloads require data to be stored and accessed reliably, consistently, and efficiently, even when the containers or nodes are restarted, moved, or scaled.
Storage provider tools refer to software solutions that assist in managing data for workloads on Kubernetes. They offer a range of functionalities, including volume provisioning, replication, backup, encryption, compression, and performance tuning. These tools seamlessly integrate with Kubernetes APIs and concepts like Persistent Volume (PV) Persistent Volume Claim (PVC) and Storage Class. Storage provider tools can be classified into distributed file systems, object storage systems, block storage systems, and database clustering tools.
This article aims to highlight the five storage provider tools for Kubernetes that’re worth knowing about: SeaweedFS, Vitess, TiKV, Rook, and OpenEBS. We will delve into their definitions of working mechanisms and the benefits they bring to users of Kubernetes. Additionally, we will share some real-life use cases or success stories where these tools have proven valuable on Kubernetes deployments. By the time you finish reading this article, you will gain an understanding of the landscape of storage provider options available for Kubernetes and obtain insights on choosing the most suitable tool based on your specific requirements.
1. Rook
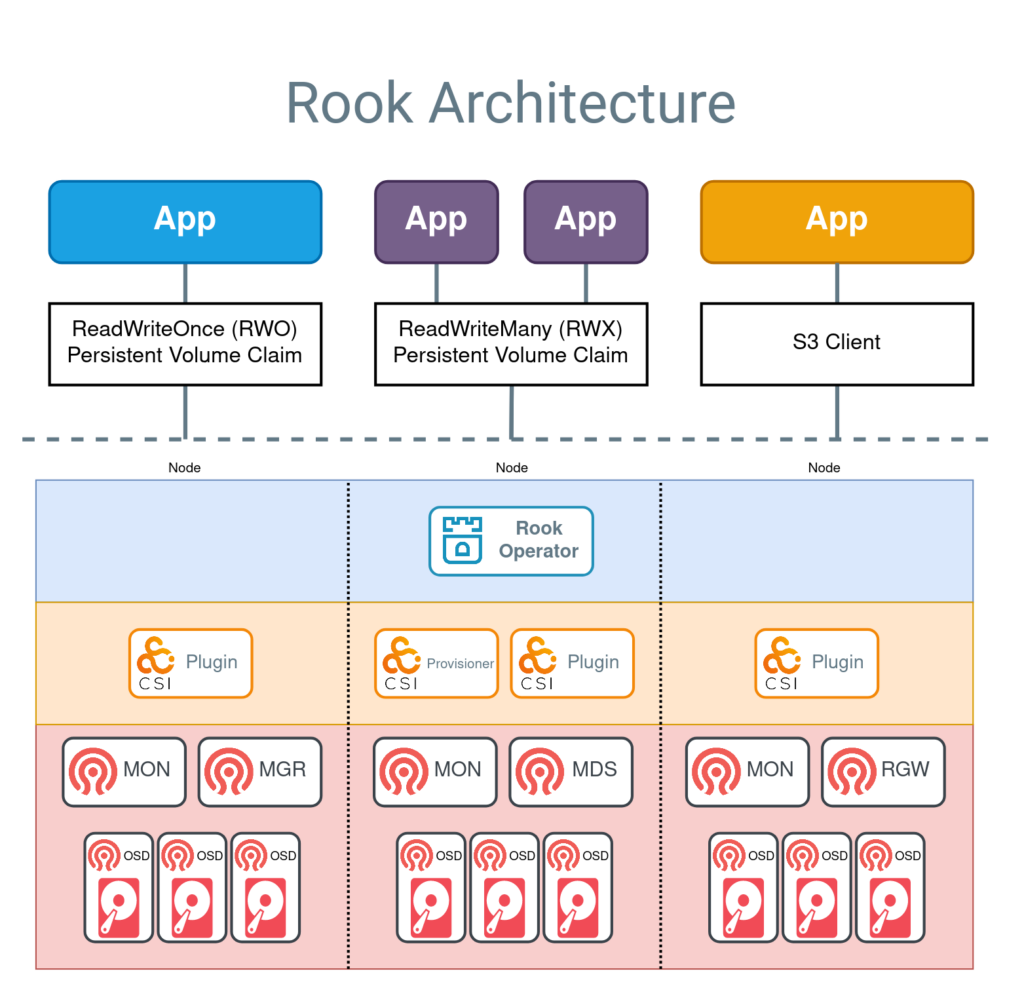
Rook is a cloud-native storage orchestrator for Kubernetes that automates the deployment, management, and scaling of storage services such as Ceph, EdgeFS, Cassandra, etc. It is designed to provide a unified and consistent way of provisioning and consuming storage across different storage providers and platforms. It consists of two main components: the Rook operator and the Rook cluster. The Rook operator is a Kubernetes controller that watches for custom resource definitions (CRDs) and creates and manages the Rook cluster accordingly. The Rook cluster is a collection of pods that run the storage service and expose it as persistent volumes (PVs) or object storage to the Kubernetes applications.
Benefits of Rook as a storage provider tool:
- It provides multi-cloud storage, as it can run on any Kubernetes cluster, whether it is on-premises, in the cloud, or on the edge, and leverage the underlying storage resources, such as local disks, cloud disks, or network-attached storage (NAS).
- It provides Kubernetes native storage as it integrates with Kubernetes APIs and concepts, such as PV, PVC, Storage Class, etc., and supports dynamic provisioning, snapshotting, cloning, resizing, and backup of storage volumes.
- It is an open source leader, as it is developed and maintained by the Rook community and the Cloud Native Computing Foundation (CNCF) and supports a wide range of storage providers and platforms, such as Ceph, EdgeFS, Cassandra, CockroachDB, MinIO, etc.
- It provides connection pooling, shard management, and load balancing, as it handles the complexity of connecting to and managing the storage service and distributes the load and data across the cluster nodes.
- It provides self-healing and self-managing as it monitors the health and performance of the storage service, automatically recovers from failures, rebalances the data, and scales the cluster.
Use Cases Of Rook
- Clouds Sky: Clouds Sky is a cloud service provider that offers Kubernetes-based solutions for enterprises and developers. It uses Rook to provide scalable and reliable storage for its customers, using Ceph as the storage provider and MinIO as the object storage gateway.
- CLEW Medical: CLEW Medical is a medical technology company that provides predictive analytics and clinical optimization solutions for intensive care units (ICUs). It uses Rook to store and process large amounts of patient data, using EdgeFS as the storage provider and Cassandra as the database.
- Arista Networks: Arista Networks is a network technology company that provides cloud networking solutions for data centers and campuses. It uses Rook to store and manage configuration data and telemetry data, using CockroachDB as the storage provider and database.
2. OpenEBS
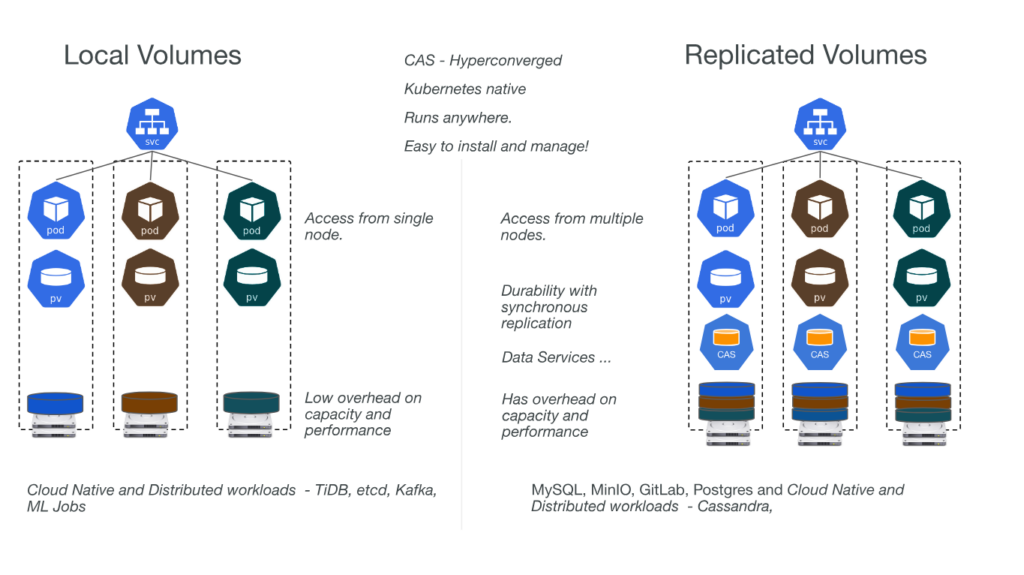
OpenEBS is a containerized block storage solution for Kubernetes that turns any storage available on the Kubernetes worker nodes into local or distributed persistent volumes. It is designed to provide flexible and dynamic storage provisioning and management for stateful applications on Kubernetes. It consists of two main components: the OpenEBS control plane and the OpenEBS data plane. The OpenEBS control plane is responsible for creating and managing the storage classes, persistent volume claims, and persistent volumes. The OpenEBS data plane is composed of storage engines, such as Jiva, cStor, LocalPV, etc., that provide the actual storage functionality and performance.
Benefits of OpenEBS
- It provides no vendor lock-in, as it is open source and free, and does not depend on any proprietary or cloud-specific storage solutions.
- It helps to save money on storage, backups, and more, as it uses the existing storage resources on the Kubernetes nodes, and supports features such as thin provisioning, compression, deduplication, snapshotting, cloning, backup, and restore.
- It can run anywhere, as it can work on any Kubernetes cluster, whether it is on-premises, in the cloud, or on the edge, and supports any type of storage, such as SSD, HDD, NVMe, etc.
- It provides granular control as it allows users to customize and optimize the storage parameters, such as replication factor, I/O performance, availability, etc., for each application or workload.
- It provides high availability and resilience, as it replicates the data across multiple nodes and zones and automatically recovers from node or disk failures.
Use Cases Of OpenEBS
- Agnes Intelligence: Agnes Intelligence is a legal technology company that provides artificial intelligence solutions for document analysis and review. It uses OpenEBS to store and process large volumes of legal documents, using cStor as the storage engine and MinIO as the object storage gateway.
- ByteDance: ByteDance is a global internet technology company that operates various platforms and services, such as TikTok, Douyin, Toutiao, etc. It uses OpenEBS to store and serve massive amounts of user-generated content, such as videos, images, sounds, etc., using LocalPV as the storage engine and TiKV as the database.
- [Clouds Sky]((https://cloudssky.com/en/wir-ueber-uns/geschaeftsfuehrung/): Clouds Sky is a cloud service provider that offers Kubernetes-based solutions for enterprises and developers. It uses OpenEBS to provide scalable and reliable storage for its customers, using Jiva as the storage engine and Rook as the storage orchestrator.
3. SeaweedFS
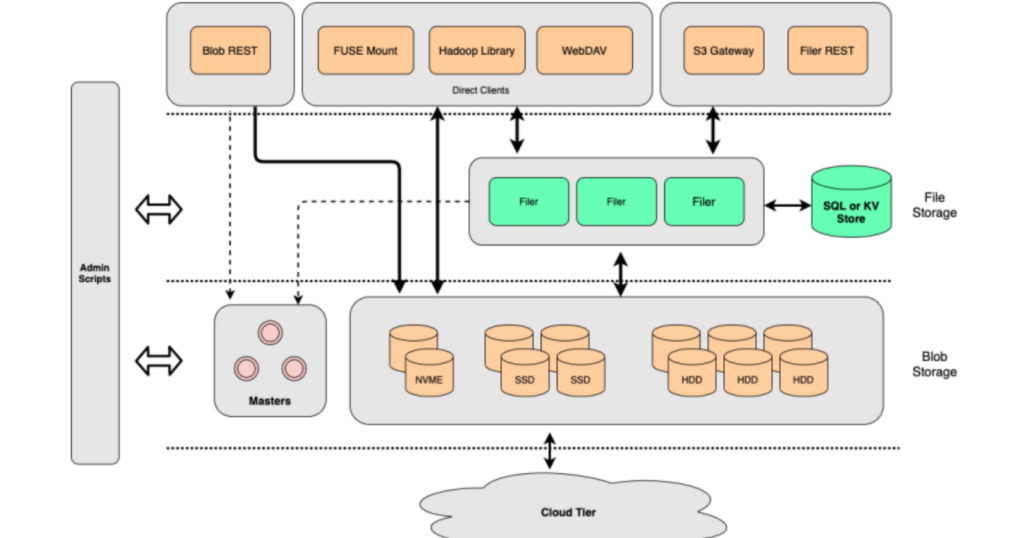
SeaweedFS is a fast distributed storage system for blobs, objects, files, and data lake, with O(1) disk seek, cloud tiering, and various metadata stores. It is designed to store and serve billions of files fast and cost-effectively. It consists of three main components: volume servers, filers, and master servers. Volume servers store the actual data in chunks, filers provide a hierarchical namespace and metadata management, and master servers manage the cluster topology and balance the load.
Benefits of SeaweedFS
- It is easy to deploy and scale, as it can run on any Kubernetes cluster with minimal configuration and resources.
- It is compatible with various protocols and APIs, such as the S3 API, POSIX FUSE mount, Hadoop, and WebDAV, making it easy to integrate with existing applications and tools.
- It supports encryption and erasure coding, ensuring data security and durability across multiple nodes and regions.
- It supports cloud tiering, allowing data to be moved between different storage tiers, such as SSD, HDD, or cloud storage, based on usage patterns and policies.
Use Cases Of SeaweedFS
- Game servers: SeaweedFS can provide fast and scalable storage for game assets, such as images, sounds, videos, etc., and serve them to millions of players worldwide.
- Object storage service: SeaweedFS can act as a self-hosted object storage service, similar to AWS S3 or Google Cloud Storage, and offer low-cost and high-performance storage for any kind of data.
- Recommendation systems: SeaweedFS can store and serve large-scale feature vectors and embeddings for machine learning models, such as recommendation systems, and enable online feature store and inference.
- Data lake: SeaweedFS can store and process massive amounts of structured and unstructured data, such as logs, events, metrics, etc., and support various data formats and engines, such as Parquet, ORC, Spark, Presto, etc.
4. TiKV
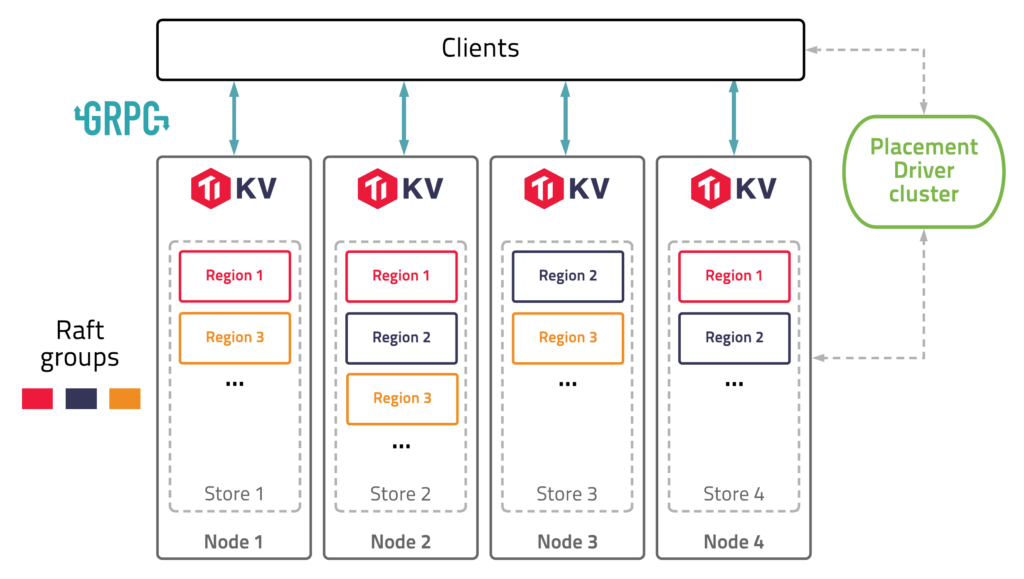
TiKV is a distributed, transactional key-value database, powered by Raft, that provides both raw and [ACID-compliant transactional APIs]( ACID-compliant transactional APIs). It is designed to provide low-latency, high-throughput, and consistent data storage for large-scale applications that require strong data consistency and reliability. It consists of three main components: PD, TiKV, and TiDB. PD is the cluster manager that handles leader election, load balancing, and configuration. TiKV is the storage layer that stores and serves data in key-value pairs, using RocksDB as the underlying engine. TiDB is the SQL layer that provides a MySQL-compatible interface and supports distributed transactions and analytics.
Benefits of TiKV
- It has low and stable latency, as it uses a multi-Raft consensus algorithm to ensure data consistency and availability and a multi-level cache to improve performance.
- It has high scalability, as it can handle petabytes of data and thousands of concurrent requests, and it supports dynamic data sharding and rebalancing.
- It is easy to use, as it provides a simple and unified API for both raw and transactional data access and supports various client libraries and drivers, such as Java, Go, Rust, Python, etc.
- It is open source and free, as it is developed and maintained by the TiKV community and the Cloud Native Computing Foundation (CNCF) and licensed under Apache 2.0.
- It has customizable consistency, as it allows users to choose between linearizability, causality, and eventual consistency, depending on their application requirements.
Use Cases Of TiKV
- Apache Solr: Apache Solr is a popular open-source search platform that provides full-text search, faceting, highlighting, clustering, and more. It uses TiKV as its storage backend and provides a scalable, reliable, and fast search service.
- Micro-service messages: TiKV can be used as a message queue for microservice architectures, as it supports pub/sub, push/pull, and request/reply patterns and guarantees message ordering, delivery, and durability.
- Kafka implementations: TiKV can be used as a replacement for Kafka, as it supports streaming data ingestion, processing, and delivery and offers better performance, scalability, and reliability.
5. Vitess
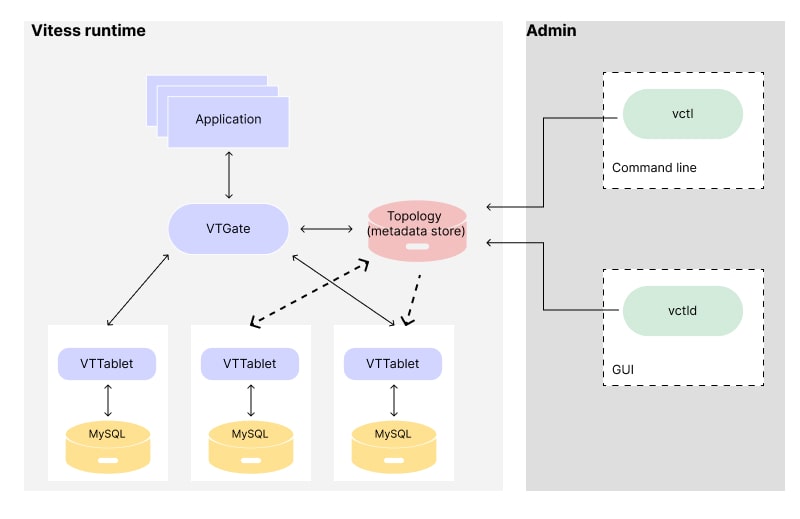
Vitess offers a solution for scaling MySQL databases. It comes with a range of features, including sharding, caching, query modifications, failover mechanisms, and backup capabilities. This system is specifically designed to ensure web applications that rely on MySQL databases can achieve performance, availability, and scalability. The four main components of Vitess are vtgate (a proxy server that directs queries to the shards), vttablet (an intermediary layer that manages replication, backup processes, and recovery), vtctld (a user web interface for cluster management and monitoring), and vtorc (a tool used for orchestrating failover and making changes to the database’s topology).
Benefits of Vitess:
- It is scalable, as it can handle millions of queries per second and terabytes of data across thousands of nodes.
- It is reliable, as it can survive node failures, network partitions, and data center outages and automatically recover from them.
- It is MySQL-compatible, as it supports most of the MySQL features and syntax and can be accessed by any MySQL client or driver.
- It is cloud-native, as it is designed to run on Kubernetes and leverage its features, such as service discovery, load balancing, health checks, etc.
- It is easy to deploy and manage, as it provides a declarative API and a Helm chart for installing and configuring Vitess on Kubernetes.
Use Cases Of Vitess
- TiDB: TiDB is a distributed SQL database that is compatible with MySQL and supports hybrid transactional and analytical processing (HTAP). It uses Vitess as its storage layer and provides a scalable, consistent, and high-performance database service.
- Zetta: Zetta is a cloud-native database service that provides a unified data platform for online transaction processing (OLTP) and online analytical processing (OLAP). It uses Vitess as its core component and supports SQL, NoSQL, and NewSQL interfaces.
- Tidis: Tidis is a distributed NoSQL database that is compatible with Redis and TiDB. It uses Vitess as its storage engine and provides a high-performance, scalable, and reliable key-value store.
- Titan: Titan is a distributed graph database that is compatible with Apache TinkerPop and Gremlin. It uses Vitess as its storage backend and provides a scalable, consistent, and expressive graph model.
- JuiceFS: JuiceFS is a distributed file system that is compatible with POSIX and Hadoop. It uses Vitess as its metadata store and provides a high-performance, scalable, and cost-effective file system.
Final Thoughts
In this article, we’ve covered the top 5 storage provider tools for Kubernetes that you should be familiar with. These include Rook, OpenEBS, SeaweedFS, TikV, and Vitess. We’ve delved into their functionalities, operational mechanisms, and the advantages they bring to Kubernetes users. Additionally, we’ve shared real-life scenarios and success stories where these tools have proven valuable within a Kubernetes environment.
These storage provider tools have different features and advantages, depending on the type and scale of the data, the performance and reliability requirements, the compatibility and integration options, and the cost and complexity factors.
Here are some general recommendations or tips for choosing the best storage provider tool for different scenarios or requirements:
- If you need a fast and scalable storage system for blobs, objects, files, and data lakes, you can use SeaweedFS, which supports various protocols and APIs, such as S3, POSIX, Hadoop, and WebDAV, and offers encryption and erasure coding.
- If you need a database clustering system for horizontal scaling of MySQL, you can use Vitess, which provides built-in sharding, caching, query rewriting, failover, backup, and more and is compatible with MySQL and cloud-native.
- If you need a distributed, transactional key-value database, you can use TiKV, which provides both raw and ACID-compliant transactional APIs, and has low and stable latency, high scalability, and customizable consistency.
- If you need a cloud-native storage orchestrator for Kubernetes, you can use Rook, which automates deployment, management, and scaling of storage services such as Ceph, EdgeFS, Cassandra, etc. and provides multi-cloud storage and Kubernetes native storage.
- If you need a containerized block storage solution for Kubernetes, you can use OpenEBS, which turns any storage available on the Kubernetes worker nodes into local or distributed persistent volumes and provides no vendor lock-in, granular control, and high availability.
We trust that you found this article informative and gained insights from it. If you have any inquiries or thoughts to share, please don’t hesitate to leave a comment. We are eager to receive your feedback and assist you with any questions on storage requirements related to Kubernetes.

