
Kubernetes is a platform that enables you to automate the process of deploying, scaling, and managing applications that are contained within containers. It operates on the idea of clusters, which consist of nodes (either virtual machines or physical machines) for running your applications and services. Additionally, Kubernetes offers functionalities like service discovery, load balancing, storage orchestration, and automatic recovery.
Machine learning (ML) involves developing systems that can acquire knowledge from data and make predictions or decisions. ML tasks often include resource activities like data preparation, training models, serving models, and monitoring their performance. There are advantages to utilizing Kubernetes for ML workloads, such as:
- Scalability: Kubernetes has the ability to adjust the scale of your ML applications based on demand and resource availability. Additionally you can utilize Kubernetes to distribute your ML workloads, across nodes or clusters enhancing both performance and efficiency.
- Portability: Kubernetes can run your ML applications on any environment, such as on-premises, cloud, or hybrid. You can also use Kubernetes to move your ML applications from one environment to another without changing the code or the configuration.
- Reproducibility: Kubernetes can ensure that your ML applications run in the same way every time, regardless of the underlying infrastructure. You can also use Kubernetes to version and track your ML applications and their dependencies, such as data, models, and libraries.
- Collaboration: Kubernetes allows you to easily collaborate and share your ML applications with developers and users. Additionally Kubernetes offers integration with tools and platforms, like CI/CD, monitoring and logging enabling you to streamline your ML workflows.
However when it comes to deploying machine learning applications, on Kubernetes there are challenges that need to be addressed. These challenges may include:
-
Complexity: Kubernetes can be quite challenging to learn and requires effort, for configuration and management. Additionally you must have a grasp of utilizing Kubernetes resources and components including pods, services, deployments and statefulsets.
-
Compatibility: Kubernetes does not support all the ML frameworks and libraries out of the box. You also need to ensure that your ML applications are compatible with the Kubernetes API and the container runtime.
-
Consistency: Kubernetes does not guarantee that your ML applications will run in the same way on different nodes or clusters. You also need to ensure that your ML applications have consistent access to the data and the models, especially when they are updated or modified.
To address these obstacles and make the most of Kubernetes for ML tasks, it’s essential to utilize tools that can streamline and enhance your ML workflows on Kubernetes. This article aims to introduce you to five top-notch tools that can aid you in your ML endeavors on Kubernetes. Additionally, we’ll showcase real-world examples. Use cases to illustrate how these tools can elevate your ML experience on Kubernetes. The selection criteria for these tools are as follows:
- Functionality: The tool should provide a specific functionality or solution for ML on Kubernetes, such as data management, model training, model serving, or model optimization.
- Usability: The tool should be easy to use and integrate with Kubernetes and other ML tools and platforms.
- Popularity: The tool should have a large and active user base and community, as well as a high number of stars and forks on GitHub.
- Innovation: The tool should be up-to-date and innovative, as well as support the latest trends and technologies in ML and Kubernetes.
The top 5 tools for ML on Kubernetes are:
- Kubeflow
- Feast
- KServe
- OpenML
- Volcano
Let’s take a closer look at each of these tools and see how they can help you with ML on Kubernetes.
Kubeflow
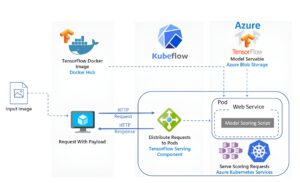
Kubeflow is an open-source platform that enables you to automate the process of deploying, scaling, and managing your machine learning (ML) workflows on Kubernetes. The core idea behind Kubeflow revolves around clusters, which are essentially groups of nodes (either virtual machines) responsible for running your applications and services. Additionally, Kubeflow offers a variety of features, including service discovery, load balancing, storage orchestration, and self-healing capabilities.
Some of the features and components of Kubeflow
-
Notebooks: Kubeflow includes services to create and manage interactive Jupyter notebooks. You can customize your notebook deployment and your compute resources to suit your data science needs. Experiment with your workflows locally, then deploy them to a cloud when you’re ready.
-
TensorFlow model training: Kubeflow provides a custom TensorFlow training job operator that you can use to train your ML model. In particular, Kubeflow’s job operator can handle distributed TensorFlow training jobs. Configure the training controller to use CPUs or GPUs and to suit various cluster sizes.
-
Model serving: Kubeflow supports a TensorFlow Serving container to export trained TensorFlow models to Kubernetes. Kubeflow is also integrated with Seldon Core, an open source platform for deploying machine learning models on Kubernetes, NVIDIA Triton Inference Server for maximized GPU utilization when deploying ML/DL models at scale, and MLRun Serving, an open-source serverless framework for deployment and monitoring of real-time ML/DL pipelines.
-
Pipelines: Kubeflow Pipelines is a comprehensive solution for deploying and managing end-to-end ML workflows. Use Kubeflow Pipelines for rapid and reliable experimentation. You can schedule and compare runs, and examine detailed reports on each run.
-
Multi-framework: Kubeflow supports not only TensorFlow, but also other popular ML frameworks and libraries, such as PyTorch, Apache MXNet, MPI, XGBoost, and Chainer. You can also integrate Kubeflow with other tools and platforms, such as Istio and Ambassador for ingress, Nuclio as a fast multi-purpose serverless framework, and Pachyderm for managing your data science pipelines.
Feast
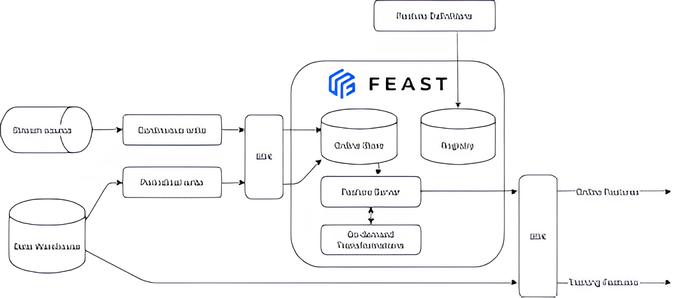
Feast is a platform that enables you to store and serve attributes, or variables known as features, for machine learning models on Kubernetes. These features can include customer demographics, product ratings, or sensor readings, which are used as inputs for the ML models. Feast offers an approach to defining, managing, and accessing features throughout stages of the ML lifecycle in different environments.
Some of the features and advantages of Feast
-
Point-in-time correctness: Feast ensures that the features used for training and serving are historically accurate and consistent. Feast uses timestamps to join features from different sources and to retrieve the correct feature values at any point in time.
-
Data validation: Feast helps you to validate the quality and distribution of your features. Feast integrates with TensorFlow Data Validation (TFDV) to generate statistics and anomalies for your features. You can also use Feast to monitor and alert on feature drift and skew.
-
Integration with popular ML frameworks and platforms: Feast supports various ML frameworks and libraries, such as TensorFlow, PyTorch, XGBoost, and Scikit-learn. Feast also integrates with Kubeflow Pipelines, Google Cloud AI Platform, and Amazon SageMaker to enable end-to-end ML workflows on Kubernetes.
Some examples of use cases of using Feast for feature engineering and management on Kubernetes
-
Customer churn prediction: You can use Feast to store and serve features related to customer behavior, such as purchase frequency, recency, and amount. You can then use these features to train and deploy a ML model that predicts the likelihood of customer churn. Feast ensures that the features are consistent and up-to-date across different environments and platforms.
-
Fraud detection: You can use Feast to store and serve features related to transaction data, such as amount, location, and device. You can then use these features to train and deploy a ML model that detects fraudulent transactions. Feast ensures that the features are accurate and aligned with the historical data and the current state of the system.
-
Recommendation system: You can use Feast to store and serve features related to user preferences, product attributes, and ratings. You can then use these features to train and deploy a ML model that recommends relevant products to users. Feast ensures that the features are comprehensive and scalable to handle large volumes of data and requests.
KServe
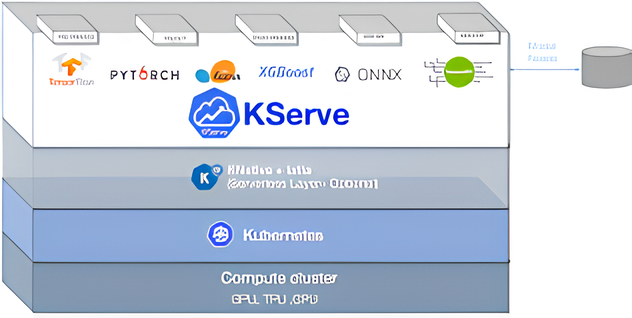
KServe is a Kubernetes-based tool that provides a standardized API endpoint for deploying and managing machine learning (ML) models on Kubernetes. KServe is based on the concept of inference services, which are Kubernetes custom resources that encapsulate the configuration and status of your ML models. KServe allows you to automate the deployment, scaling, and monitoring of your ML models on Kubernetes with minimal code and configuration.
Some of the features and advantages of KServe
-
Model fetching: KServe can fetch your ML models from various sources, such as local storage, cloud storage, or model registries. You can also specify the model format, such as TensorFlow SavedModel, ONNX, or PMML, and the model framework, such as TensorFlow, PyTorch, or Scikit-learn.
-
Model loading: KServe can load your ML models into memory and cache them for faster inference. You can also specify the number of model replicas and the resource requests and limits for your ML models. KServe supports GPU acceleration and scale-to-zero for your ML models.
-
Model scaling: KServe can scale your ML models up or down according to the demand and the available resources. You can also use horizontal pod autoscaling (HPA) or Kubernetes metrics server to adjust the number of model replicas based on CPU or memory utilization. KServe also supports cluster autoscaling to add or remove nodes from your Kubernetes cluster as needed.
-
Model observability: KServe can monitor and log the performance and behavior of your ML models. You can use Prometheus and Grafana to collect and visualize the metrics of your ML models, such as requests, latency, errors, and throughput. You can also use Jaeger and Zipkin to trace the requests and responses of your ML models. KServe also integrates with Istio and Knative to provide service mesh and eventing capabilities for your ML models.
Some examples of use cases of using KServe for model serving and inference on Kubernetes
-
Sentiment analysis: You can use KServe to deploy and serve a ML model that analyzes the sentiment of text inputs, such as tweets, reviews, or comments. You can use KServe to fetch your ML model from a cloud storage or a model registry, load it into memory, and scale it according to the traffic. You can also use KServe to monitor and log the metrics and traces of your ML model, such as the number of requests, the latency, and the accuracy.
-
Image classification: You can use KServe to deploy and serve a ML model that classifies images into different categories, such as animals, plants, or objects. You can use KServe to fetch your ML model from a local storage or a cloud storage, load it into memory, and scale it according to the traffic. You can also use KServe to leverage GPU acceleration and scale-to-zero for your ML model, as well as to monitor and log the metrics and traces of your ML model, such as the number of requests, the latency, and the accuracy.
-
Model experimentation: You can use KServe to deploy and serve multiple versions of your ML model and compare their performance and behavior. You can use KServe to fetch your ML models from different sources, load them into memory, and scale them according to the traffic. You can also use KServe to implement canary rollouts, A/B testing, or multi-armed bandits for your ML models, as well as to monitor and log the metrics and traces of your ML models, such as the number of requests, the latency, and the accuracy.
-## OpenML
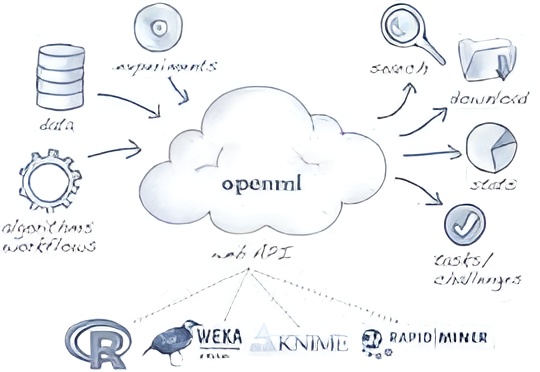
OpenML is an open-source platform that allows you to share and collaborate on machine learning (ML) experiments and datasets on Kubernetes. OpenML is based on the concept of clusters, which are groups of nodes (physical or virtual machines) that run your applications and services. OpenML also provides features such as service discovery, load balancing, storage orchestration, and self-healing.
Some of the features and advantages of OpenML
-
Reproducibility: OpenML records exactly which datasets and library versions are used, so that nothing gets lost. For every experiment, the exact pipeline structure, architecture, and all hyperparameter settings are automatically stored. OpenML flows wrap around tool-specific implementations that can be serialized and later deserialized to reproduce models and verify results.
-
Benchmarking: OpenML allows you to run systematic benchmarks, large-scale experiments, and learn from previous experiments. OpenML provides easy-to-use, curated suites of ML tasks to standardize and improve benchmarking. OpenML also supports an open, ongoing, and extensible benchmark framework for Automated Machine Learning (AutoML) systems.
-
Integration with AutoML tools and frameworks: OpenML supports various AutoML tools and frameworks that use OpenML to speed up the search for the best models, such as autosklearn, SageMaker AutoML, Azure AutoML, and GAMA. OpenML also integrates with other tools and platforms, such as CI/CD, monitoring, and logging.
Some examples of use cases of using OpenML for ML experimentation and optimization on Kubernetes
-
Data analysis: You can use OpenML to explore and visualize thousands of ML datasets, uniformly formatted, easy to load, and organized online. You can also use OpenML to generate statistics and anomalies for your datasets, and to monitor and alert on data drift and skew.
-
Model selection: You can use OpenML to compare and contrast millions of reproducible ML experiments on thousands of datasets, and to make informed decisions. You can also use OpenML to implement canary rollouts, A/B testing, or multi-armed bandits for your models, and to monitor and log the metrics and traces of your models.
-
Model optimization: You can use OpenML to learn from millions of experiments how to tune algorithms, such as parameter importance, default learning, and symbolic defaults. [You can also use OpenML to leverage GPU acceleration and scale-to-zero for your models, and to optimize your models using AutoML tools and frameworks](OpenML Overview – The Khronos Group Inc).
Volcano
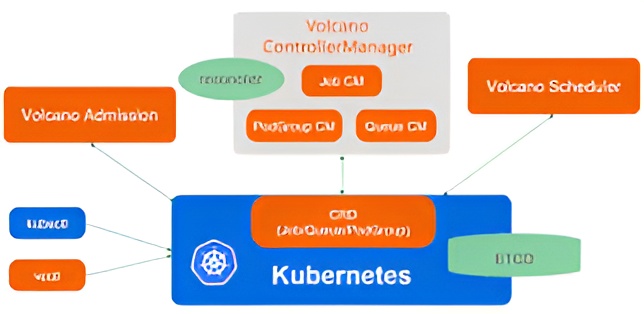
Volcano is a platform that anyone can use to run demanding tasks on Kubernetes. It offers a batch scheduling feature that’s often necessary for various types of resource intensive tasks, like machine learning (ML) bioinformatics and big data applications.
Some of the features and advantages of Volcano
-
Performance: Volcano optimizes the performance of your ML workloads by providing various scheduling policies, such as gang scheduling, fair-share scheduling, and queue scheduling. Volcano also supports GPU acceleration and scale-to-zero for your ML workloads.
- Scalability: Volcano can scale your ML workloads up or down according to the demand and the available resources. You can also use horizontal pod autoscaling (HPA) or cluster autoscaling to adjust the number of pods or nodes for your ML workloads.
-
Usability: Volcano inherits the design of Kubernetes APIs, allowing you to easily run your ML workloads on Kubernetes with minimal code and configuration. You can also use Volcano to integrate your ML workloads with other tools and platforms, such as Kubeflow, Flink, Spark, and TensorFlow.
Some examples of use cases of using Volcano for ML on Kubernetes
-
ML training: You can use Volcano to train your ML models on Kubernetes using various ML frameworks and libraries, such as TensorFlow, PyTorch, MXNet, and XGBoost. Volcano ensures that your ML training jobs are scheduled and executed efficiently and reliably on Kubernetes.
-
ML inference: You can use Volcano to serve your ML models on Kubernetes using various ML serving platforms, such as TensorFlow Serving, Seldon Core, and NVIDIA Triton Inference Server. Volcano ensures that your ML inference services are scaled and monitored properly on Kubernetes.
-
ML pipeline: You can use Volcano to orchestrate your ML pipeline on Kubernetes using various ML pipeline platforms, such as Kubeflow Pipelines, MLRun, and Argo. Volcano ensures that your ML pipeline tasks are coordinated and synchronized on Kubernetes.
Final Thoughts
Thank you for taking the time to read this article. Within this piece, we have presented the five tools that can assist you in your machine learning endeavors on Kubernetes. Additionally, we have included examples. Use cases that demonstrate how these tools can enhance your overall machine learning experience on Kubernetes To summarize the key takeaways from this article, they are:
Kubernetes is useful for ML workloads, as it provides features such as scalability, portability, reproducibility, and collaboration. However, Kubernetes also poses some challenges for ML workloads, such as complexity, compatibility, and consistency.
To overcome these challenges and to leverage the benefits of Kubernetes for ML workloads, you need to use some tools that can simplify and enhance your ML workflows on Kubernetes. The criteria for selecting these tools are functionality, usability, popularity, and innovation.
The top 5 tools for ML on Kubernetes are Kubeflow, Feast, KServe, OpenML, and Volcano. Each of these tools provides a specific functionality or solution for ML on Kubernetes, such as data management, model training, model serving, model experimentation, or model optimization.
The strengths and weaknesses of these tools
-
Kubeflow: Kubeflow is a comprehensive platform that simplifies ML workflows on Kubernetes. Kubeflow supports various ML frameworks and components, such as notebooks, TensorFlow model training, model serving, pipelines, and multi-framework support. However, Kubeflow can be difficult to install and configure, and it may not support all the ML frameworks and libraries that you need.
-
Feast: Feast is a platform that provides a consistent way to store and serve features for ML models on Kubernetes. Feast ensures that the features are historically accurate and consistent, and it integrates with popular ML frameworks and platforms, such as TensorFlow, PyTorch, XGBoost, and Kubeflow Pipelines. However, Feast can be complex to use and maintain, and it may not support all the data sources and formats that you need.
-
KServe: KServe is a tool that provides a standardized API endpoint for deploying and managing ML models on Kubernetes. KServe supports various ML serving platforms, such as TensorFlow Serving, Seldon Core, NVIDIA Triton Inference Server, and MLRun Serving. KServe also provides features such as model fetching, loading, scaling, and observability. However, KServe can be limited in its functionality and flexibility, and it may not support all the model formats and frameworks that you need.
-
OpenML: OpenML is a platform that allows you to share and collaborate on ML experiments and datasets on Kubernetes. OpenML records and reproduces ML experiments, and it supports various AutoML tools and frameworks, such as autosklearn, SageMaker AutoML, Azure AutoML, and GAMA. OpenML also provides features such as data analysis, model selection, and model optimization. However, OpenML can be challenging to use and integrate, and it may not support all the ML tasks and datasets that you need.
-
Volcano: Volcano is a platform that allows you to run high-performance workloads on Kubernetes. Volcano features powerful batch scheduling capability that Kubernetes cannot provide but is commonly required by many classes of high-performance workloads, including ML, bioinformatics, and big data applications. Volcano also provides features such as performance, scalability, and usability. However, Volcano can be incompatible with some Kubernetes resources and components, and it may not support all the workloads and applications that you need.
Some recommendations and best practices for using the tools for ML on Kubernetes
-
Choose the tool that best suits your ML needs and goals. You may not need to use all the tools, or you may need to use a combination of tools, depending on your ML scenario and requirements.
-
Learn the basics of Kubernetes and how to use its resources and components, such as pods, services, deployments, and statefulsets. This will help you to understand and troubleshoot the tools and their interactions with Kubernetes.
-
Follow the documentation and tutorials of the tools and their integrations with other tools and platforms. This will help you to install, configure, and use the tools and their features correctly and effectively.
-
Join the community and forums of the tools and their users. This will help you to get support, feedback, and updates on the tools and their development.
We hope that this article has provided you with insights and helpful instructions on utilizing ML tools on Kubernetes. If you have any inquiries or thoughts please don’t hesitate to reach out to us or leave a comment below. We genuinely appreciate hearing from you and gaining knowledge from your experiences. Thank you for investing your time and attention. Happy Machine Learning on Kubernetes!
Leave a Reply