
Imagine you’re building a multi-node Kubernetes cluster. You’ve set up an application running as microservices and an Elasticsearch database up and running in the cluster. The application is using an Amazon RDS managed database service that runs outside the cluster. This application has data services inside and outside the application. Data from the elastic-search database is used by the cluster through Kubernetes persistent volume components.
The following diagram illustrates the architecture:
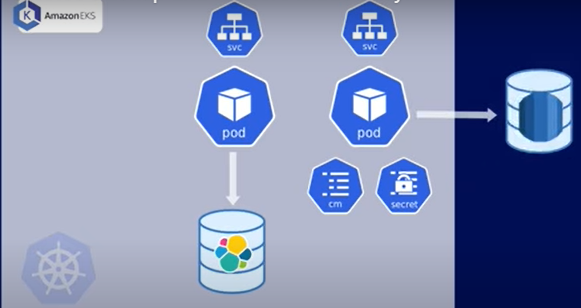
The RDS database is stored on a physical database on AWS, but the elastic-search database also needs to be backed up in a physical storage unit using a cloud service like AWS or an on-premise server. This should be done because in a scenario where the infrastructure where your cluster is running fails, all the pods, services, and configurations in the cluster will be lost, which will force you to recreate the entire cluster again with the same cluster state and application configurations. Another scenario is that if the elastic-search database is corrupted or hacked, you will have to recreate the cluster to its current working state.
Traditional backup and disaster recovery (BDR) solutions are ill-equipped to handle the complexities of containerized environments, particularly those orchestrated by Kubernetes.
These legacy BDR tools are designed to protect individual servers and their applications, which doesn’t align with the distributed nature of Kubernetes deployments. Kubernetes applications often span multiple clouds and data centers, making them vulnerable to data loss if traditional BDR methods are employed.
Furthermore, the temporary nature of containers poses a significant challenge for traditional BDR tools. Containers are frequently created, destroyed, and restarted, making it difficult to maintain consistent backups using legacy approaches.
Backing up and restoring Kubernetes clusters is not an easy task. It involves several requirements that need to be addressed, such as:
Capturing the state of both Kubernetes objects and persistent volumes. Kubernetes objects, such as pods, services, deployments, and secrets, store the configuration and metadata of the applications and their dependencies. Persistent volumes, such as PVCs, PVs, and storage classes, store the actual data of the applications and their state. Both types of resources need to be backed up and restored consistently and coherently to ensure the functionality and reliability of the applications.
In today’s data-driven world, businesses rely on Kubernetes to manage containerized applications. However, with the growing complexity of Kubernetes deployments, ensuring data protection and storage management becomes increasingly crucial. Kubernetes backup solutions play a pivotal role in safeguarding business-critical data by providing automated backups, data recovery, storage optimization, and disaster recovery planning. These solutions are designed to handle the dynamic nature of Kubernetes environments, ensuring seamless data protection and storage management even in clustered setups.
With a range of Kubernetes backup and storage solutions available, selecting the most suitable option requires careful consideration. To help you find the right solution, we’ve compiled a list of the top 5 Kubernetes backup and storage solutions, evaluating each platform’s technological capabilities, features, functionality, and overall benefits.
Velero
This is a popular open-source tool that enables backup and restore of Kubernetes resources and persistent volumes across clusters and clouds. It supports various storage providers, such as AWS, Azure, GCP, DigitalOcean, and more. It also allows scheduling, hooks, and custom plugins.
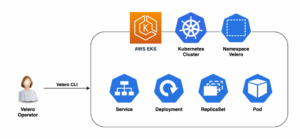
Velero is a tool that helps you manage the backup and restore of your Kubernetes cluster resources and persistent volumes. You can use Velero to take snapshots of your cluster at a given point in time and restore them to a different cluster or a different state. You can also use Velero to migrate your workloads across clusters or clouds or to perform disaster recovery in case of a cluster failure or data loss.
Features and functionality of Velero
-
Backup and restore of Kubernetes resources and persistent volumes, either manually or on a schedule.
-
Support for various storage providers and locations, such as AWS S3, Azure Blob Storage, Google Cloud Storage, DigitalOcean Spaces, and more.
-
Ability to filter and select the resources and volumes to backup and restore, based on namespaces, labels, or annotations.
-
Ability to run custom commands or scripts before and after the backup and restore operations, using hooks.
-
Ability to extend the functionality of Velero using custom plugins, such as backup and restore drivers, object store plugins, or volume snapshotter plugins.
-
Ability to monitor and troubleshoot the backup and restore operations, using logs, events, and metrics.
Pros and Cons of Velero
-
Pros:
- It is open-source and free to use, with an active community and documentation.
- It is easy to install and use, with a simple command-line interface and a Helm chart.
- It is compatible and interoperable with other Kubernetes tools and components, such as kubectl, Helm, and kustomize.
- It is flexible and customizable, with various options and parameters to configure the backup and restore operations.
-
Cons:
- It does not support backup and restore of cluster-level resources, such as CRDs, RBAC, or admission controllers, by default. You need to use a separate tool, such as kubeadm, to backup and restore these resources.
- It does not support backup and restore of external data sources, such as databases or message queues, that are not managed by Kubernetes. You need to use a separate tool, such as pg_dump, to backup and restore these data sources.
- It does not provide a graphical user interface or a web management console. You need to use the command-line interface or a third-party tool, such as Arkade, to manage and monitor the backup and restore operations.
Use Cases of Velero
-
Backup and restore: You can use Velero to backup and restore your Kubernetes cluster resources and persistent volumes, either manually or on a schedule. For example, you can use Velero to backup your cluster every night, and restore it to a previous state in case of a failure or error. You can also use Velero to backup and restore specific resources or volumes, based on your needs and preferences.
-
Disaster recovery: You can use Velero to perform disaster recovery of your Kubernetes cluster, in case of a cluster failure or data loss. For example, you can use Velero to backup your cluster to a remote storage location, and restore it to a different cluster or a different cloud provider, in case your original cluster becomes unavailable or corrupted. You can also use Velero to restore your cluster to a different region or zone, in case of a natural disaster or a network outage.
-
Migration: You can use Velero to migrate your workloads across clusters or clouds, without losing the state or configuration of your applications and data. For example, you can use Velero to backup your cluster from one cloud provider, and restore it to another cloud provider, in case you want to switch or optimize your cloud services. You can also use Velero to backup your cluster from one Kubernetes version, and restore it to another Kubernetes version, in case you want to upgrade or downgrade your cluster.
Portworx
Portworx is a comprehensive cloud-native storage platform that provides backup and restore capabilities for Kubernetes applications and data. It offers application-aware backups, zero RPO disaster recovery, database as a service, and multi-cloud migration. It also integrates with other tools, such as Velero, Kasten, and Cohesity.
Portworx is also a platform that helps you manage and optimize your storage for your Kubernetes applications and data. You can use Portworx to provision, protect, and migrate your persistent volumes across clusters and clouds. You can also use Portworx to backup and restore your applications and data with high performance and reliability.
Features and functionality of Portworx
-
Backup and restore of Kubernetes applications and data, either manually or on a schedule, with application-aware snapshots, clones, and backups.
-
Support for various storage providers and locations, such as AWS EBS, Azure Managed Disks, Google Persistent Disks, DigitalOcean Block Storage, and more.
-
Ability to backup and restore the entire application stack, including the Kubernetes objects, the persistent volumes, and the external data sources, such as databases or message queues.
-
Ability to perform zero RPO disaster recovery, by replicating the application and data across clusters or clouds, and switching over to the secondary cluster or cloud in case of a failure or disaster.
-
Ability to provide database as a service, by automating the provisioning, backup, restore, and scaling of databases, such as PostgreSQL, MySQL, MongoDB, Cassandra, and more.
-
Ability to migrate applications and data across clusters or clouds, without downtime or data loss, by using Portworx’s PX-Motion feature.
-
Ability to integrate with other tools, such as Velero, Kasten, and Cohesity, to leverage their features and functionality for backup and restore operations.
Pros and Cons of Portworx
-
Pros:
- It is a complete and enterprise-grade solution for cloud-native storage, backup, and restore, with advanced features and functionality.
- It is easy to install and use, with a graphical user interface and a web management console, as well as a command-line interface and a Helm chart.
- It is compatible and interoperable with other Kubernetes tools and components, such as kubectl, Helm, and kustomize, as well as other Portworx products, such as PX-Backup, PX-Central, and PX-Enterprise.
- It is flexible and customizable, with various options and parameters to configure the storage, backup, and restore operations, as well as the ability to create custom plugins and integrations.
-
Cons:
- It is not open-source and free to use, but rather a commercial and licensed product, with different pricing and licensing plans.
- It may require additional hardware and software resources, such as disks, nodes, or licenses, to run and scale the platform and its features.
- It may have some limitations and dependencies, such as the minimum Kubernetes version, the supported storage providers, or the required Portworx components, to use some of the features and functionality.
Use Cases of Portworx
-
Backup and restore: You can use Portworx to backup and restore your Kubernetes applications and data, either manually or on a schedule, with application-aware snapshots, clones, and backups. For example, you can use Portworx to backup your application and data every hour, and restore them to a previous state in case of a failure or error. You can also use Portworx to backup and restore the entire application stack, including the Kubernetes objects, the persistent volumes, and the external data sources, such as databases or message queues.
-
Disaster recovery: You can use Portworx to perform disaster recovery of your Kubernetes applications and data, in case of a cluster failure or data loss. For example, you can use Portworx to replicate your application and data across clusters or clouds, and switch over to the secondary cluster or cloud in case of a failure or disaster. You can also use Portworx to perform zero RPO disaster recovery, by ensuring that your application and data are always in sync and available across clusters or clouds.
-
Database as a service: You can use Portworx to provide database as a service, by automating the provisioning, backup, restore, and scaling of databases, such as PostgreSQL, MySQL, MongoDB, Cassandra, and more. For example, you can use Portworx to create and manage your databases on Kubernetes, and backup and restore them with high performance and reliability. You can also use Portworx to scale your databases horizontally or vertically, based on your needs and preferences.
Kasten
Kasten is a Kubernetes-native backup solution that protects cloud-native applications and data by storing on-demand backups in an independent storage repository. It supports various storage providers, such as AWS, Azure, GCP, and more. It also provides policy-driven automation, application consistency, and encryption. It provides a solution that helps you backup and restore your Kubernetes applications and data with ease and efficiency. You can use Kasten to create and manage backups of your cluster resources and persistent volumes and store them in a separate and secure storage repository. You can also use Kasten to restore your applications and data to the same or a different cluster with minimal downtime and data loss.
Features and functionality of Kasten
- Backup and restore of Kubernetes resources and persistent volumes, either manually or on a schedule, with application-consistent snapshots and backups.
- Support for various storage providers and locations, such as AWS S3, Azure Blob Storage, Google Cloud Storage, and more.
- Ability to backup and restore the entire application stack, including the Kubernetes objects, the persistent volumes, and the external data sources, such as databases or message queues.
- Ability to provide policy-driven automation, by defining and applying backup and restore policies based on namespaces, labels, or annotations, and enforcing them across clusters or clouds.
- Ability to encrypt the backups and the storage repository, using AES-256 encryption, and manage the encryption keys securely.
- Ability to monitor and troubleshoot the backup and restore operations, using logs, events, and alerts.
Pros and Cons of Kasten
-
Pros:
- It is a Kubernetes-native and cloud-native solution that leverages the features and capabilities of the platform, such as CRDs, operators, controllers, and hooks.
- It is easy to install and use, with a graphical user interface and a web management console, as well as a command-line interface and a Helm chart.
- It is compatible and interoperable with other Kubernetes tools and components, such as kubectl, Helm, and kustomize, as well as other Kasten products, such as K10 and KubeMQ.
- It is flexible and customizable, with various options and parameters to configure the backup and restore operations, as well as the ability to create custom plugins and integrations.
-
Cons:
- It is not open-source and free to use, but rather a commercial and licensed product, with different pricing and licensing plans.
- It may require additional hardware and software resources, such as disks, nodes, or licenses, to run and scale the solution and its features.
- It may have some limitations and dependencies, such as the minimum Kubernetes version, the supported storage providers, or the required Kasten components, to use some of the features and functionality.
Use Cases of Kasten
- Backup and restore: You can use Kasten to backup and restore your Kubernetes applications and data, either manually or on a schedule, with application-consistent snapshots and backups. For example, you can use Kasten to backup your application and data every day, and restore them to a previous state in case of a failure or error. You can also use Kasten to backup and restore the entire application stack, including the Kubernetes objects, the persistent volumes, and the external data sources, such as databases or message queues.
-
Disaster recovery: You can use Kasten to perform disaster recovery of your Kubernetes applications and data, in case of a cluster failure or data loss. For example, you can use Kasten to backup your application and data to a remote storage location, and restore them to a different cluster or a different cloud provider, in case your original cluster becomes unavailable or corrupted. You can also use Kasten to encrypt your backups and the storage repository, to ensure the security and privacy of your data.
-
Application mobility: You can use Kasten to migrate your applications and data across clusters or clouds, without downtime or data loss, by using Kasten’s application mobility feature. For example, you can use Kasten to backup your application and data from one cluster or cloud provider, and restore them to another cluster or cloud provider, in case you want to switch or optimize your cloud services. You can also use Kasten to backup your application and data from one Kubernetes version, and restore them to another Kubernetes version, in case you want to upgrade or downgrade your cluster.
Stash
Stash is a Kubernetes operator that uses restic or Kubernetes CSI Driver VolumeSnapshotter functionality to backup and restore Kubernetes volumes mounted in workloads, stand-alone volumes, and databases. It supports various storage providers, such as AWS, Azure, GCP, DigitalOcean, and more. It also enables pre- and post-hooks, migration, and a web management console.
![]()
Stash is also a tool that helps you backup and restore your Kubernetes volumes with ease and efficiency. You can use Stash to create and manage backups of your volumes mounted in workloads, such as deployments, statefulsets, or daemonsets, as well as stand-alone volumes, such as PVCs or PVs, and databases, such as PostgreSQL, MySQL, MongoDB, and more. You can also use Stash to restore your volumes to the same or a different cluster with minimal downtime and data loss.
Features and functionality of Stash
- Backup and restore of Kubernetes volumes, either manually or on a schedule, using restic or Kubernetes CSI Driver VolumeSnapshotter functionality.
- Support for various storage providers and locations, such as AWS S3, Azure Blob Storage, Google Cloud Storage, DigitalOcean Spaces, and more.
- Ability to backup and restore the entire volume data, including the file system metadata, such as permissions, ownership, and timestamps.
- Ability to run custom commands or scripts before and after the backup and restore operations, using pre and post hooks.
- Ability to migrate volumes across clusters or clouds, without downtime or data loss, by using Stash’s VolumeReplication feature.
- Ability to monitor and troubleshoot the backup and restore operations, using logs, events, and metrics.
- Ability to manage and configure the backup and restore operations, using a graphical user interface and a web management console, as well as a command-line interface and a Helm chart.
Pros and Cons of Stash
-
Pros:
- It is open-source and free to use, with an active community and documentation.
- It is easy to install and use, with a simple and declarative configuration using Kubernetes CRDs and annotations.
- It is compatible and interoperable with other Kubernetes tools and components, such as kubectl, Helm, and kustomize, as well as other Stash products, such as Stash Enterprise and Stash Operator.
- options and parameters to configure the backup and restore operations, as well as the ability to create custom plugins and integrations.
-
Cons:
- It does not support backup and restore of cluster-level resources, such as CRDs, RBAC, or admission controllers, by default. You need to use a separate tool, such as kubeadm, to backup and restore these resources.
- It does not support backup and restore of external data sources, such as databases or message queues, that are not managed by Kubernetes. You need to use a separate tool, such as pg_dump, to backup and restore these data sources.
- It does not provide encryption of the backups or the storage repository, by default. You need to use a separate tool, such as gpg, to encrypt and decrypt your data.
Use Cases of Stash
-
Backup and restore: You can use Stash to backup and restore your Kubernetes volumes, either manually or on a schedule, using restic or Kubernetes CSI Driver VolumeSnapshotter functionality. For example, you can use Stash to backup your volumes every week, and restore them to a previous state in case of a failure or error. You can also use Stash to backup and restore the entire volume data, including the file system metadata, such as permissions, ownership, and timestamps.
-
Snapshotting: You can use Stash to create and manage snapshots of your Kubernetes volumes, using Kubernetes CSI Driver VolumeSnapshotter functionality. For example, you can use Stash to create and delete snapshots of your volumes on demand, and use them to restore your volumes to a specific point in time. You can also use Stash to list and inspect the snapshots of your volumes, and compare them with the current state of your volumes.
-
Encryption: You can use Stash to encrypt and decrypt your Kubernetes volumes, using a separate tool, such as gpg. For example, you can use Stash to encrypt your volumes before backing them up to a remote storage location, and decrypt them after restoring them to a local cluster. You can also use Stash to encrypt and decrypt your volumes on the fly, using pre and post hooks.
Kube-Dump
This is a simple utility that dumps Kubernetes cluster resources as pure YAML manifests without unnecessary metadata. It can save both name-spaced and cluster-wide resources and commit them to a git repository. It can also archive and rotate dump archives.

Kube-Dump is also a tool that helps you backup and restore your Kubernetes cluster resources as pure YAML manifests without unnecessary metadata. You can use Kube-Dump to dump all or selected resources from your cluster and save them as YAML files in a local or remote directory. You can also use Kube-Dump to commit the YAML files to a git repository and track the changes and history of your cluster resources. You can also use Kube-Dump to archive and rotate the dump archives, saving disk space and bandwidth.
Features and functionality of Kube-Dump
- Dump of Kubernetes resources, either manually or on a schedule, as pure YAML manifests without unnecessary metadata, such as creationTimestamp, resourceVersion, or selfLink.
- Support for both namespaced and cluster-wide resources, such as pods, services, deployments, secrets, CRDs, RBAC, and more.
- Ability to filter and select the resources to dump, based on namespaces, labels, or annotations, or using a custom resource list file.
- Ability to commit the dump files to a git repository, and track the changes and history of the cluster resources, using git commands and tools.
- Ability to archive and rotate the dump archives, and compress them using gzip or bzip2, and delete the old archives based on a retention policy.
- Ability to monitor and troubleshoot the dump operations, using logs, events, and metrics.
Pros and Cons of Kube-Dump
-
Pros:
- It is open-source and free to use, with an active community and documentation.
- It is easy to install and use, with a simple and declarative configuration using Kubernetes CRDs and annotations.
- It is compatible and interoperable with other Kubernetes tools and components, such as kubectl, Helm, and kustomize, as well as other git tools and services, such as GitHub, GitLab, and Bitbucket.
- It is lightweight and efficient, with minimal overhead and resource consumption, and fast and reliable dump operations.
-
Cons:
- It does not support backup and restore of persistent volumes, by default. You need to use a separate tool, such as Velero, to backup and restore these volumes.
- It does not support backup and restore of external data sources, such as databases or message queues, that are not managed by Kubernetes. You need to use a separate tool, such as pg_dump, to backup and restore these data sources.
- It does not provide encryption of the dump files or the storage repository, by default. You need to use a separate tool, such as gpg, to encrypt and decrypt your data.
Use Cases of Kube-Dump
- Backup and restore: You can use Kube-Dump to backup and restore your Kubernetes cluster resources as pure YAML manifests without unnecessary metadata. For example, you can use Kube-Dump to dump all or selected resources from your cluster, and save them as YAML files in a local or remote directory. You can also use Kube-Dump to restore your cluster resources from the YAML files, by applying them to the same or a different cluster, using kubectl or Helm commands.
-
Compression: You can use Kube-Dump to compress your dump files and archives, and save disk space and bandwidth. For example, you can use Kube-Dump to archive and rotate the dump archives, and compress them using gzip or bzip2, and delete the old archives based on a retention policy. You can also use Kube-Dump to decompress the dump files and archives, and extract them to a local or remote directory, using tar or unzip commands.
-
Filtering: You can use Kube-Dump to filter and select the resources to dump, based on namespaces, labels, or annotations, or using a custom resource list file. For example, you can use Kube-Dump to dump only the resources that belong to a specific namespace, or have a specific label or annotation, or are listed in a custom resource list file. You can also use Kube-Dump to exclude the resources that you do not want to dump, by using the –exclude flag or the –exclude-from-file flag.
Comparing and Contrasting The Top 5 Tools
To compare and contrast the top 5 tools to recommend the best one for different use cases and scenarios, we can use the following table:

Based on the table, we can recommend the best tool for different use cases and scenarios, as follows:
-
If you want a simple and lightweight tool that can backup and restore your cluster resources as pure YAML manifests without unnecessary metadata, and can commit them to a git repository, you can use Kube-Dump.
-
If you want a flexible and customizable tool that can backup and restore your volumes mounted in workloads, stand-alone volumes, and databases, using restic or Kubernetes CSI Driver VolumeSnapshotter functionality, and can run custom commands or scripts before and after the backup and restore operations, you can use Stash.
-
If you want a Kubernetes-native and cloud-native solution that can backup and restore your entire application stack, including the Kubernetes objects, the persistent volumes, and the external data sources, and can provide policy-driven automation, application consistency, and encryption, you can use Kasten.
-
-
If you want a comprehensive and enterprise-grade solution for cloud-native storage, backup, and restore, with advanced features and functionality, such as application-aware backups, zero RPO disaster recovery, database as a service, and multi-cloud migration, you can use Portworx.
-
If you want a popular and open-source tool that can backup and restore your Kubernetes resources and persistent volumes across clusters and clouds, and can support various storage providers, and can allow scheduling, hooks, and custom plugins, you can use Velero.
Tips and best practices for backup and restore of Kubernetes clusters
-
Plan and design your backup and restore strategy, based on your needs and preferences, such as the frequency, granularity, consistency, and location of your backups and restores, and the tools and methods you will use.
-
Test and verify your backup and restore operations, before and after performing them, to ensure the functionality and reliability of your applications and data, and to identify and resolve any issues or errors.
- Monitor and optimize your backup and restore operations, using logs, events, metrics, and alerts, to track the performance and status of your backup and restore operations, and to improve the efficiency and quality of your backup and restore operations.
If you have any inquiries or thoughts to share, please don’t hesitate to leave a comment. We are eager to receive your feedback and assist you with any questions on storage requirements related to Kubernetes.
Leave a Reply